Let’s cut through the jargon. Reverse ETL is the process of moving data from your central data warehouse back into the operational tools your business teams live in every day.
Think of it like this: your data warehouse is a master chef who has taken raw ingredients from all over and prepared the perfect, gourmet meal. Reverse ETL is the delivery service that brings that finished meal directly to the people who ordered it—your sales, marketing, and support teams—right inside the apps they already use, like Salesforce or HubSpot.
Flipping the Traditional Data Flow on Its Head
For years, data pipelines were a one-way street. The main goal was always to pull information into a central place for analysis. This process, known as ETL (Extract, Transform, Load), is great for building reports and dashboards. The problem? It often leaves your best insights locked away in the data warehouse, accessible only to data analysts or BI specialists.
Reverse ETL completely changes the game by creating a two-way highway for your data. It takes the cleaned, enriched, and modeled data—your single source of truth—and pushes it out to the front lines. This is what we mean by “operationalizing” your data; it turns passive insights into real-world actions that drive smarter business decisions.
Why This is a Game-Changer for Your Teams
The impact is immediate. Business teams no longer have to work with stale information or wait for a data person to send them a spreadsheet. With reverse ETL, they get the freshest, most relevant data delivered directly into their existing workflows.
This empowers them to personalize customer interactions, score and prioritize sales leads, and run automated campaigns with an accuracy they just couldn’t achieve before. The growth of this approach has exploded, thanks to the widespread adoption of cloud data warehouses like Snowflake and Google BigQuery.
In fact, the Reverse ETL market was recently estimated to be worth around $485 million globally, a number fueled by the simple need to make warehouse data useful in everyday business apps. You can find more insights on this growing market and see why so many companies are jumping on board.
At its heart, reverse ETL is all about closing the loop between seeing an insight and taking action on it. It’s the final mile that ensures your most valuable data doesn’t just sit in a warehouse but actively works for you across the entire organization.
The “before and after” picture for a typical team is pretty stark. Let’s look at how daily life changes for a marketing team once they plug in a reverse ETL solution.
A Quick Look Before and After Reverse ETL
| Operational Task | Before Reverse ETL (Manual and Stale Data) | After Reverse ETL (Automated and Fresh Data) |
|---|---|---|
| List Segmentation | Manually export CSVs from multiple sources, clean them up, and upload them to the email tool. Data is often days or weeks old. | Customer segments are automatically updated in the marketing platform based on the latest product usage and purchase data from the warehouse. |
| Lead Scoring | Relies on basic demographic data or website activity captured within the CRM. It’s often inaccurate and misses key signals. | Leads are scored dynamically using a rich, 360-degree customer view, including product engagement, support tickets, and billing status. |
| Personalization | Campaigns use generic merge tags like “First Name.” Deeper personalization is too complex and time-consuming. | Emails and ads are personalized with specific user behaviors, like “users who used Feature X but not Feature Y,” pulled directly from the warehouse. |
| Audience Syncing | Manually creating custom audiences for ad platforms like Google or Facebook. It’s a slow process prone to human error. | Audiences are automatically synced and refreshed daily, ensuring ad spend is targeted at the most relevant users, reducing waste. |
As you can see, the contrast in efficiency, accuracy, and strategic power is night and day. This shift from manual drudgery to automated intelligence is precisely why reverse ETL has become so essential for any company that wants to be truly data-driven.
How Reverse ETL Completes Your Data Loop
To really get why reverse ETL is such a big deal, you have to look at the entire journey your data takes. In a modern setup, information doesn’t just travel one way. It’s meant to move in a continuous circle, getting smarter and more valuable with each pass. Reverse ETL is the final, crucial piece that closes that loop, turning all those brilliant insights from your data team into real-world actions on the front lines.
Remember the old way of doing things? It was a chaotic mess of point-to-point integrations. Your CRM was duct-taped to your email tool, which had a shaky connection to your payment system. Every single one of those connections was a potential breaking point, and you’d constantly find that the data in one system didn’t match the data in another. This mess creates data silos, leaving teams flying blind with incomplete or flat-out wrong information.
Reverse ETL is what finally lets you tear down those silos. It solidifies the data warehouse as the one and only source of truth for the entire company.
The Modern Data Flow Architecture
The modern data journey is so much cleaner and more logical. Instead of a free-for-all, it centralizes all your data first, letting you clean it up and enrich it before sending it back out. This ensures every team is working from the exact same playbook.
Here’s how that flow typically breaks down:
- Data Sources: This is where it all begins. Data is generated in your app databases, your CRM like Salesforce, marketing platforms like HubSpot, payment processors like Stripe, and all the other SaaS tools you use.
- Ingestion and Warehousing: Next, all that data gets pulled together (extracted) and loaded into a central cloud data warehouse—think Snowflake, Google BigQuery, or Amazon Redshift. This is the data team’s sandbox, where they transform raw data into powerful models, key metrics, and predictive scores.
- Reverse ETL: This is the “last mile” that makes everything useful. A reverse ETL tool plugs right into your warehouse, grabs the polished data—like a fresh lead score or a customer health rating—and syncs it back out.
- Operational Tools: These are the final destinations, the apps your teams live in every day. The enriched data pops up directly in tools like Salesforce, Zendesk, or Marketo, giving your people the context they need to act instantly.
This simple diagram really brings the whole process to life, showing how data moves from its source, gets refined in the warehouse, and then gets put to work in business apps through reverse ETL.
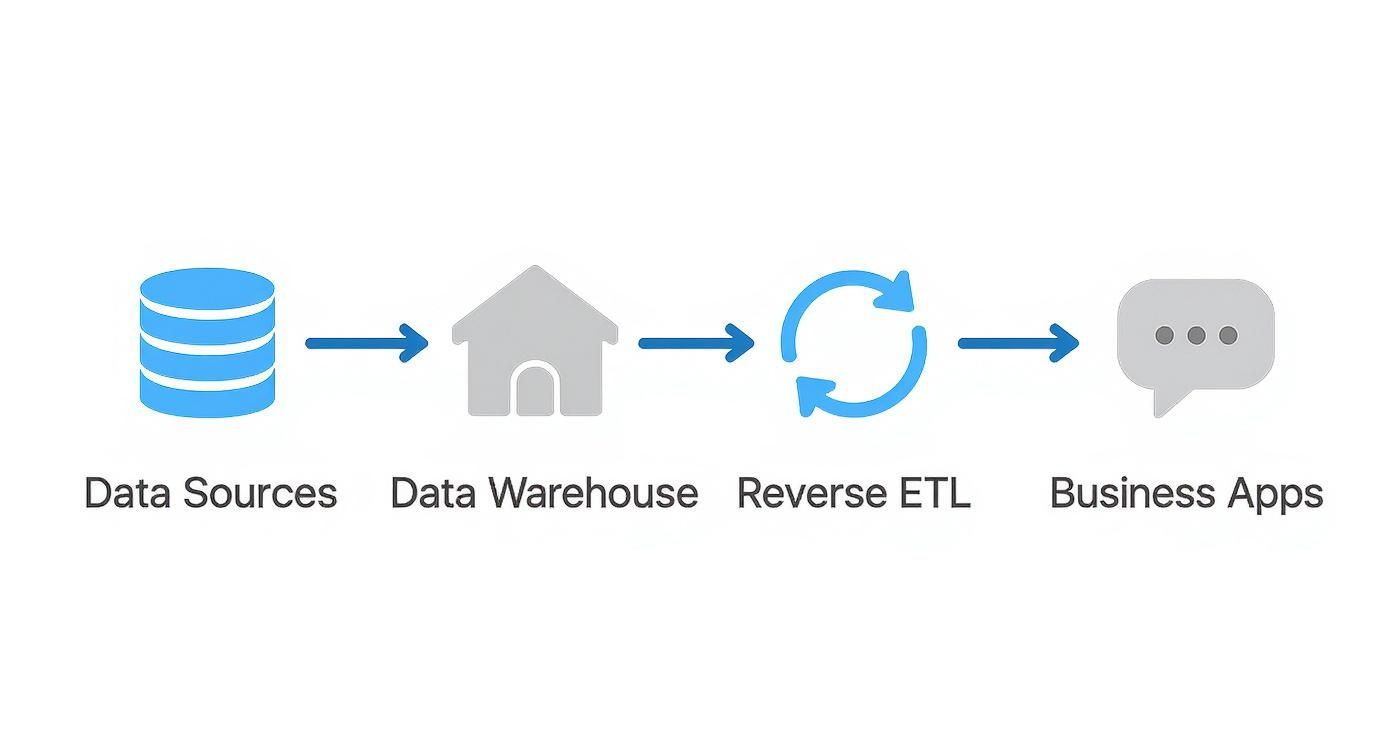
As you can see, reverse ETL is the bridge connecting your analytical world (the warehouse) to your operational world (the tools your teams use), creating one truly unified system.
Why This Closed-Loop System Wins
This isn’t just a prettier diagram; it’s a totally different philosophy for how a business should use data. The old model of fragile, one-off connections just can’t handle the speed and scale of business today.
By making the data warehouse the heart of the stack, you create a scalable, reliable system. Instead of maintaining dozens of fragile integrations, you manage one clean flow of data in and one clean flow of data out.
This approach isn’t just more resilient; it’s way more efficient. Your data team can focus on building high-quality data models once, and the reverse ETL platform handles the complicated job of piping those insights out to every tool that needs them. It guarantees that the same unified customer data fueling your executive dashboards is the exact same data your sales reps see in their CRM.
To keep this loop effective, the data coming in needs to be fresh. The process of capturing those updates in real-time is often handled by a technique you can read about in our guide on what is change data capture. This ensures the insights pushed out by reverse ETL are timely enough for your teams to actually use.
Reverse ETL vs ETL: A Simple Breakdown
It’s really easy to get these acronyms mixed up, so let’s clear the air. Reverse ETL and its well-known cousin, ETL (Extract, Transform, Load), might sound like two sides of the same coin, but they move in opposite directions and serve completely different needs in your data stack.
Let’s use a simple analogy: a restaurant kitchen.
ETL is all about getting your raw ingredients ready. Think of it as sending your team to various farms and markets (your data sources) to extract things like vegetables, spices, and meats. You bring everything back to a central kitchen (your data warehouse), where you transform it by washing, chopping, and prepping it. Finally, you load all these prepared ingredients into the pantry, ready for the chefs. The whole point of ETL is to get data in.
Reverse ETL, on the other hand, is the dinner service. It’s what happens after the chefs have cooked a beautiful meal. This process takes the finished, enriched dishes—like a perfectly calculated lead score or a customer health metric—from the kitchen and delivers them straight to your guests (your operational business tools). The goal of reverse ETL is to get actionable data out to where it can actually be used.
The Real Difference is Purpose and Flow
The fundamental distinction comes down to what you’re trying to achieve. ETL is all about analysis. It’s built to pull raw data from countless sources into one central place for reporting and business intelligence. Its destination is almost always a data warehouse or data lake, where analysts can dig into historical trends and build sophisticated models.
In contrast, reverse ETL is purely operational. Its entire reason for being is to “activate” the insights you’ve already created in the warehouse. It’s not sending data to another database for more analysis; it’s sending it directly to the SaaS apps your teams live in every day, like Salesforce, HubSpot, or Zendesk. It doesn’t move raw information; it moves curated, modeled data that’s ready for someone to act on immediately.
Think of it this way: While ETL builds your company’s entire library of knowledge, reverse ETL pulls specific, relevant chapters from that library and hands them to the people on the front lines so they can use that knowledge right in the moment.
This core difference in purpose shapes everything, from the data flow to the tools you use. ETL pipelines are designed for massive, bulk data ingestion from all over the place. Reverse ETL pipelines are built for surgical precision, making sure that key insights are synced reliably to the tools that drive your business workflows.
Comparing Data Movement Processes ETL vs Reverse ETL
To really hammer home the contrast, this table breaks down the core differences between these two essential data movement processes.
| Attribute | ETL (Extract, Transform, Load) | Reverse ETL |
|---|---|---|
| Primary Goal | To centralize raw data from many sources into a single location for analysis. | To distribute enriched data from the warehouse into operational systems for action. |
| Data Direction | FROM operational tools and databases TO the data warehouse. | FROM the data warehouse TO operational tools like CRMs and marketing platforms. |
| Type of Data | Raw, unstructured, or semi-structured data from various application sources. | Modeled, enriched, and aggregated data that has already been transformed (e.g., lead scores, customer segments). |
| Typical User | Data engineers and analytics engineers who build and maintain data infrastructure. | Data analysts define the models, but RevOps, marketing, and sales ops often manage the syncs. |
| Common Use Cases | Building dashboards, running BI reports, training machine learning models. | Powering sales alerts, personalizing marketing campaigns, enriching customer support tickets. |
At the end of the day, they are two critical parts of a modern data strategy. They aren’t in competition; they work together to make sure your organization is truly data-driven, from the C-suite all the way to the front lines.
Powerful Reverse ETL Use Cases You Can Steal

Alright, this is where the theory hits the road. It’s one thing to understand the mechanics of reverse ETL, but it’s another thing entirely to see how it actually makes a business more money. Let’s walk through some real-world examples of how smart teams are putting their data to work.
We’re not talking about abstract ideas here—these are tangible, revenue-driving plays you can replicate. Think of them as foundational moves for any modern sales, marketing, or customer success team looking for an edge.
The best part? Your teams don’t have to learn a single new tool. Reverse ETL pushes critical insights directly into the platforms they live in every day, making them smarter and far more effective without changing their workflows.
Give Your Sales Team X-Ray Vision into Product Usage
In B2B SaaS, a salesperson’s biggest challenge is knowing who to call and when. Reaching out to an account that hasn’t logged in for three months is a complete waste of time. But what if you knew exactly which accounts were bumping up against their usage limits or starting to explore new premium features? That’s a goldmine.
The Problem: Sales reps are essentially flying blind. They have no real visibility into how customers are interacting with the product, which leads to missed upsell opportunities and awkward, poorly-timed conversations.
The Fix: This is a classic reverse ETL win. You pipe product engagement data directly from your warehouse into your CRM. Suddenly, fields in Salesforce or HubSpot come alive with information like:
- Product Qualified Lead (PQL) Score: A dynamic score showing how ready an account is to buy more.
- Last Login Date: A simple but powerful indicator of account health.
- Key Feature Adoption: Flags when an account starts using sticky, high-value features.
- Usage Spike Alerts: Notifies a rep the moment an account’s activity jumps.
The Outcome: Your sales reps transform from reactive order-takers into proactive advisors. They can laser-focus their time on the hottest leads, tailor conversations around actual product behavior, and close expansion deals with near-perfect timing.
Create Marketing Campaigns People Actually Want
Let’s be honest, generic marketing is dead. Customers today expect messages that feel like they were written just for them. But how can you pull that off when your customer data is trapped in a dozen different silos?
The Problem: Marketing teams are often stuck with the basic segmentation filters in their email platforms, like “opened last email.” This makes it impossible to build campaigns based on a complete, holistic view of the customer.
The Fix: Your data warehouse becomes the command center for building audiences. The data team can craft incredibly sophisticated segments with SQL, blending everything from product usage and billing history to support tickets and website behavior. Reverse ETL then pushes these dynamic audiences straight into your marketing automation tools and ad networks.
This changes the game completely. You go from sending generic email blasts to creating precise, behavior-driven campaigns. Imagine an automated email that triggers only for users who have tried “Feature A” three times but haven’t discovered the related “Feature B.” That’s the kind of magic that happens when you put your warehouse data to work.
The Outcome: Engagement and conversion rates for marketing campaigns go through the roof. Ad spend becomes way more efficient because you’re targeting people based on real-time intent signals, not just stale demographic data.
The ROI here isn’t fuzzy. Organizations that truly embrace reverse ETL often see customer acquisition costs drop by 15-30% and conversion rates jump by 25-45%. For many, the payback period is just a few months. You can dive deeper into the numbers by checking out this analysis on reverse ETL usage statistics to see how these improvements translate to real revenue.
Arm Customer Success with a True 360-Degree View
Your Customer Success (CS) team is on the front lines, fighting churn and pushing for deeper adoption. To do their job well, they need the full story on every customer. Making them toggle between five different tabs to piece together an account’s history is a recipe for inefficiency and a terrible customer experience.
The Problem: CS managers have no single source of truth. They can’t easily see if a customer with a new support ticket also just had a failed payment or has stopped using a key feature they once loved.
The Fix: You send enriched, unified customer data from the warehouse directly into helpdesk tools like Zendesk or Intercom. This gives the CS team a complete, contextual view right where they do their work. Key data points could include:
- Customer Health Score: A single metric that summarizes an account’s overall status.
- Billing Status: A clear flag showing if the account is current or delinquent.
- Recent Product Activity: A timeline of what the user was doing right before submitting a ticket.
The Outcome: Support tickets get resolved faster and with better outcomes. The CS team can spot at-risk accounts long before they churn and have much more productive conversations because they have all the context they need in one screen. This proactive approach turns customer support from a cost center into a powerful retention engine.
Ready to Launch? Here’s How to Set Up Your First Reverse ETL Workflow

Alright, enough theory. Let’s get our hands dirty. The real value comes from putting this into practice, and thankfully, you don’t need to be a data engineer to get started. It’s all about spotting a clear business need and using the right tools to get that beautiful, clean data from your warehouse into the hands of your teams.
To make this super concrete, we’ll walk through one of the most powerful starter projects out there: syncing a Product Qualified Lead (PQL) score from your data warehouse directly into your CRM. This one move can completely change the game for your sales team.
Step 1: Start with a Crystal-Clear Business Goal
Before you even think about writing a line of SQL, you have to know what you’re trying to achieve. The goal isn’t just to “move data”—that’s how projects go to die. A vague objective like “give sales more data” is destined for failure. You need something specific, measurable, and actionable.
For our PQL example, the goal is airtight: “Enable sales reps to focus their time on the top 10% of most engaged trial users by providing a real-time PQL score inside Salesforce.” See the difference? Now everyone knows exactly what success looks like.
Step 2: Build Your Data Model in the Warehouse
This is where the real magic begins. Your data team or a sharp analyst will jump into the warehouse and start blending different data sources together with SQL to create the PQL score. This isn’t just a simple query; it’s your business logic turned into code.
The model will likely pull information from a few different places:
- Product Usage Logs: How many times did a user log in this week?
- Feature Adoption Data: Did they use key “sticky” features that correlate with conversion?
- Firmographic Info: Does their company size fit your ideal customer profile (ICP)?
The end result is a clean, simple table in your warehouse with just a few columns, like a user ID and their shiny new PQL score. If you want to get into the weeds on the foundational work here, our guide on how to build a data pipeline is a great place to start.
Step 3: Pick a Tool and Get It Connected
Now it’s time to build the bridge. You’ll grab a reverse ETL platform to connect your data warehouse to your CRM. The explosive growth in this space tells you everything you need to know about how critical this has become for modern businesses. In fact, the global Reverse ETL market was valued around $1.5 billion and is on track to hit $8 billion by 2035.
Getting set up is usually pretty painless:
- Connect Your Source: Point the tool to your data warehouse (like Snowflake or BigQuery) and authorize access.
- Connect Your Destination: Do the same for your CRM (like Salesforce or HubSpot).
- Define Your Model: Tell the tool to look at that PQL data model you just built in Step 2.
Step 4: Map the Fields and Hit Go
This is the last little bit of configuration. You just need to tell the tool exactly which data from the warehouse goes into which field in the CRM. It’s like a digital version of connect-the-dots.
- Identifier Mapping: This is the most important part! You’ll match the
user_idfrom your warehouse to theContact IDin Salesforce. Getting this right is how you avoid creating a mess of duplicate records. - Field Mapping: Next, you’ll map the
pql_scorecolumn from your data model to a custom field in your CRM you’ve created calledPQL Score.
Finally, decide how often you want this to run. For something like a PQL score, syncing every hour or two is perfect. It keeps the data fresh enough for sales to act on without putting unnecessary strain on your systems.
Pro Tip: Don’t just turn on the firehose right away. Before activating the full sync, run a small test with just a handful of records. This is your chance to catch any weird mapping issues or data type mismatches (like trying to send text into a number field) before you push updates for thousands of contacts. Once it looks good, you’re clear to hit “activate” and watch your data come to life.
Choosing the Right Reverse ETL Tool for Your Team
The reverse ETL market is crowded, and frankly, a lot of the tools look the same on the surface. But picking the right one is less about the fancy logos on their homepage and more about a few make-or-break capabilities that will determine if the tool actually helps you or just collects dust.
The first thing to check off your list is connectors. If a tool can’t talk to your data warehouse and your go-to business apps, it’s a non-starter. Don’t get wowed by a giant list of integrations; what matters is having high-quality, well-maintained connectors for the specific sources you use (like Snowflake) and the destinations you rely on daily (like Salesforce or HubSpot).
Evaluating Key Features and Functionality
Once you’ve confirmed the basic plumbing is there, it’s time to look under the hood. A great reverse ETL platform should feel less like a clunky utility and more like a trusted partner that makes your job easier.
Here are the features that separate the good from the great:
- Monitoring and Alerting: Let’s be real, data syncs fail. It’s inevitable. When one breaks, you need the tool to tell you immediately what happened and why, not leave you digging through logs trying to figure it out.
- Observability: Can you easily see where your data is coming from and where it’s going? Solid observability lets you trace data lineage, audit sync histories, and troubleshoot problems with confidence.
- Security and Compliance: This is absolutely non-negotiable, especially with customer data. The vendor must have standard certifications like SOC 2 and GDPR compliance baked in. No exceptions.
The right tool shouldn’t just move data from point A to point B. It should do so reliably, transparently, and securely, giving you the peace of mind to focus on strategy instead of constant firefighting.
Dedicated Platform vs All-in-One Suite
You’ll quickly run into a classic fork in the road: should you get a dedicated, best-of-breed reverse ETL tool, or an all-in-one data platform that just includes it as a feature?
Dedicated tools are built from the ground up for this one job. They usually offer deeper, more specialized functionality and a user experience that’s actually designed for operational teams in marketing, sales, and RevOps. The all-in-one suites can seem convenient, but their reverse ETL module is often an afterthought and can feel clunky or limited.
Many teams are leaning into a modern, composable data stack, where they pick the best tool for each part of the job. A dedicated reverse ETL platform fits perfectly into this model. To see how everything plugs together, it’s worth checking out some of the best data orchestration tools that act as the conductor for this whole symphony.
In the end, it comes down to your team’s technical skills, your budget, and where you see your data strategy heading. Start by asking the hard questions and focus on platforms that give your business users the power to activate data confidently.
Common Questions About Reverse ETL Answered
Even after getting the gist of the architecture and seeing the potential use cases, a few practical questions almost always come up when teams first look into reverse ETL. Let’s get these sorted out so you can move forward confidently.
These are the details that make the difference between just understanding the theory and actually making it work.
Is Reverse ETL Just Another Name for Data Integration?
Not quite. While it is a type of data integration, what is reverse ETL is incredibly specific about its job. It’s all about moving clean, modeled data from your central data warehouse back out to the tools your business teams use every day.
Think about traditional integration tools. They often connect apps directly, like syncing contacts from Mailchimp to Salesforce. This can quickly turn into a messy web of connections that are a nightmare to manage. Reverse ETL flips that around by using the warehouse as the single source of truth, making sure every tool gets the same consistent, reliable data.
It’s like this: point-to-point integration is like having a bunch of messengers running between departments, sometimes carrying conflicting notes. Reverse ETL is having a central command center that broadcasts verified, accurate information to everyone simultaneously.
How Is Reverse ETL Different From Custom API Scripts?
At first glance, writing your own API scripts might seem like a quick fix. But this is a classic trap that piles on technical debt fast. Custom code needs constant attention from your engineers, especially when the APIs on either end inevitably change.
Reverse ETL platforms are built to handle this exact challenge, but at scale. They give you:
- Pre-built Connectors: These save you hundreds of hours of initial development time.
- Error Handling and Retries: This makes sure your data flows don’t break just because of a temporary network blip or an API rate limit.
- Monitoring and Observability: You get dashboards and alerts that tell you immediately if a sync fails and, more importantly, why.
Basically, a reverse ETL tool productizes the kind of reliability and scale that would take an entire engineering team months or even years to build and maintain from scratch.
What Skills Does My Team Need to Get Started?
This is one of the best parts about modern reverse ETL tools—they’re surprisingly accessible. You don’t need an army of data engineers to start seeing value right away.
The one core skill you really need is strong SQL knowledge. This usually lives with a data analyst or analytics engineer who is already building data models in your warehouse. Once a model is built and ready to go, the user-friendly UIs on most platforms let people in marketing, sales, or RevOps set up and manage the syncs themselves, no code required. This puts the power directly in the hands of the people who know the business problem best.
At RevOps JET, we build the production-grade data pipelines that make these workflows a reality. Our on-demand engineering teams manage everything from complex SQL modeling to building resilient API integrations, helping you put your data to work faster and more reliably. Learn how we can help you activate your data at scale.